Posterior Sampling for Reinforcement Learning (PSRL)
Jul 24, 2023
With the Reinforcement Learning Theory group at the University of Alberta and Alberta Machine Intelligence Institute (Amii). Funded by the Emerging Leaders in the Americas (ELAP) scholarship. Special thanks to Csaba Szepesvari for the warm welcome to the lab and close up mentoring during my time in Canada!During my research internship at the University of Alberta, I was able to work on option discovery for long-horizon MDPs in the context of reinforcement learning theory research. A side project I set myself to accomplish for this purpose was replicating the experimental results from the paper (More) Efficient Reinforcement Learning via Posterior Sampling, which introduces Posterior Sampling for Reinforcement Learning (PSRL) algorithm. This article gathers some results obtained from this experience.
We first set on the task of reproducing the results from Figure 2 in the paper, but this time extending both the evaluation time by an order of magnitude and also evaluating UCRL2, not only KL-UCRL and PSRL. The following plot is the result of this experiment.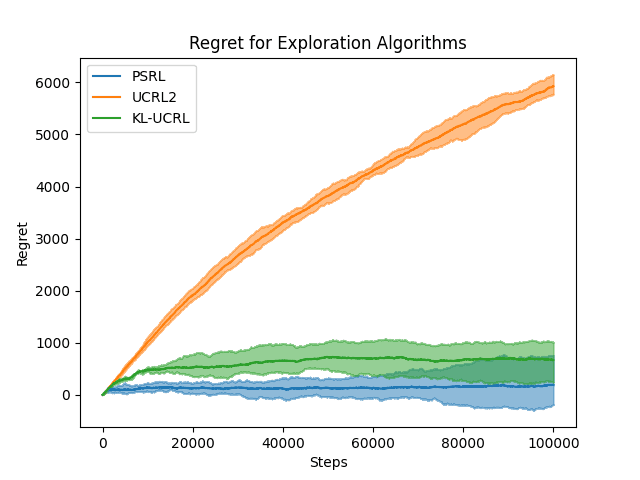
Regret for PSRL, UCRL2, and KL-UCRL on 100000 steps of RiverSwim environment.
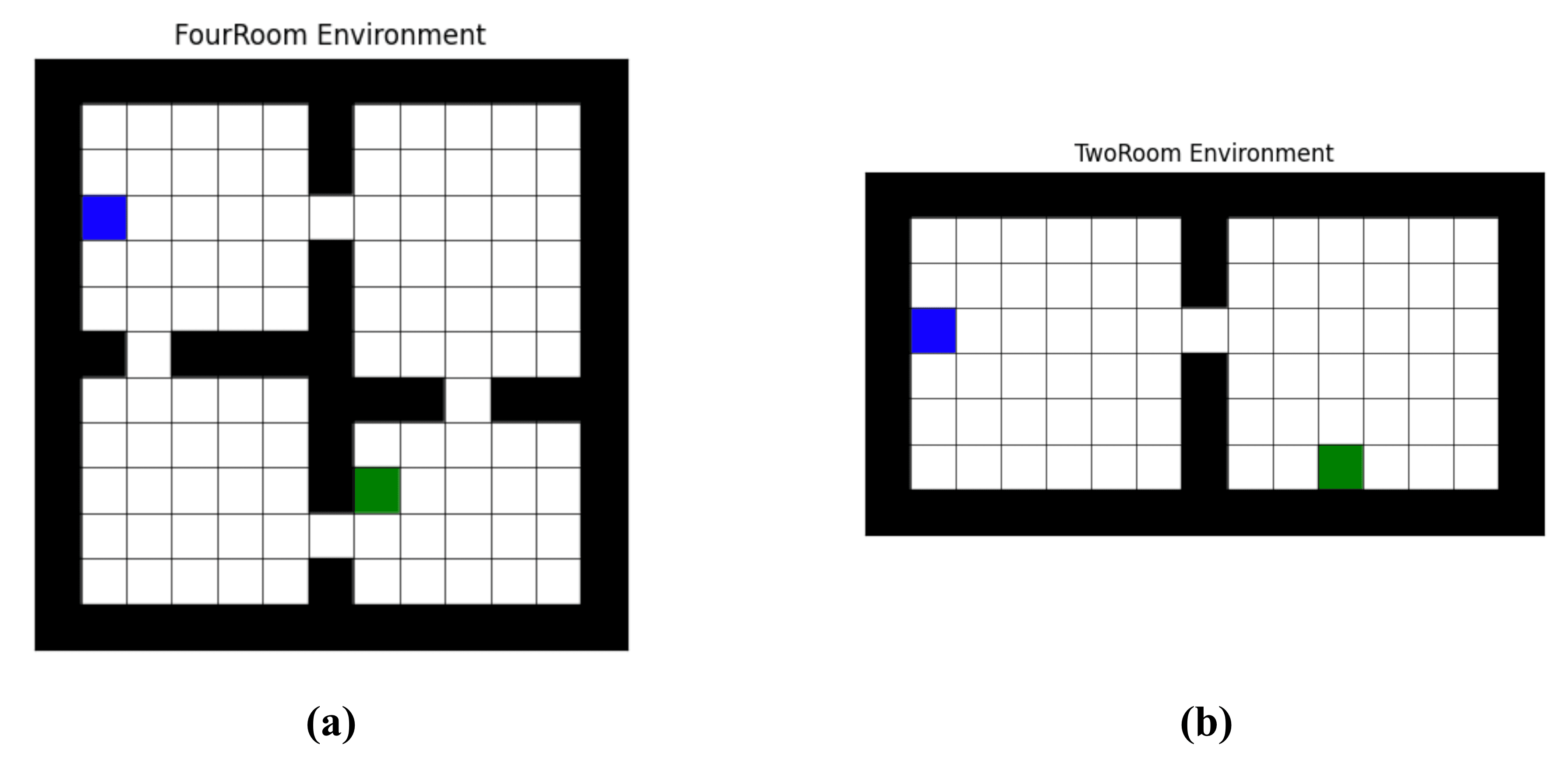
Gridworld environments: a) FourRoom, and b) TwoRoom. The blue cell represents the initial state in the environment, while the green cell represents the terminal state. All states give a reward of 0 to the agent except for the terminal state, which has a reward of 1.
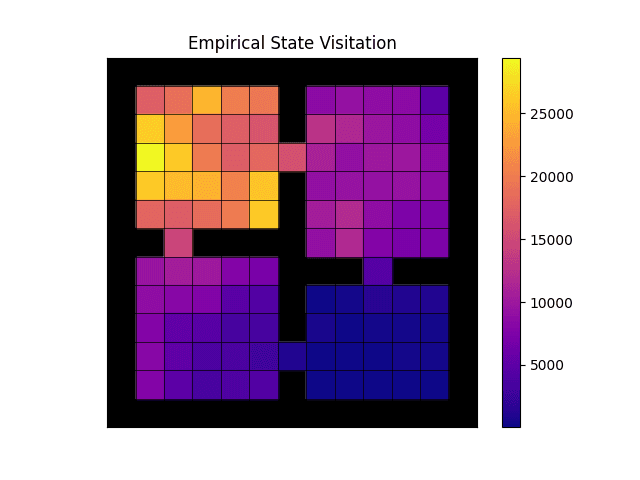
Empirical state visitation.
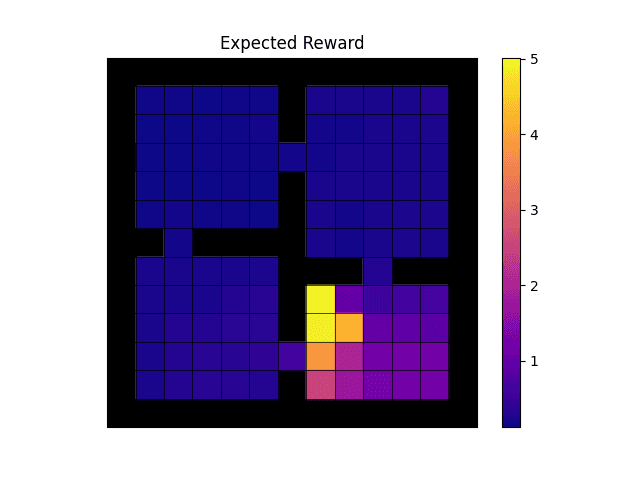
Expected reward.
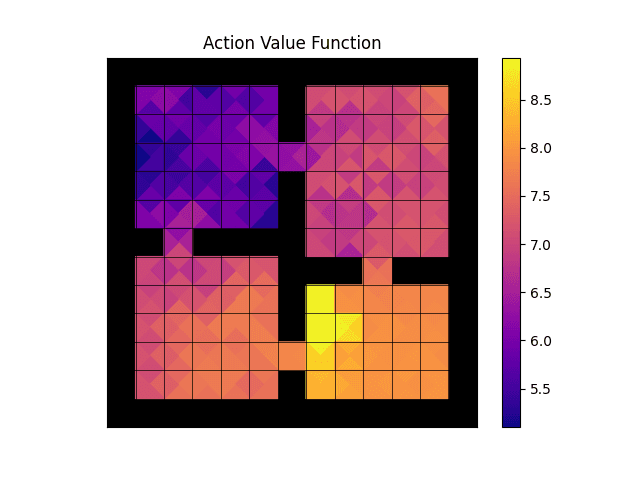
Action-value function.
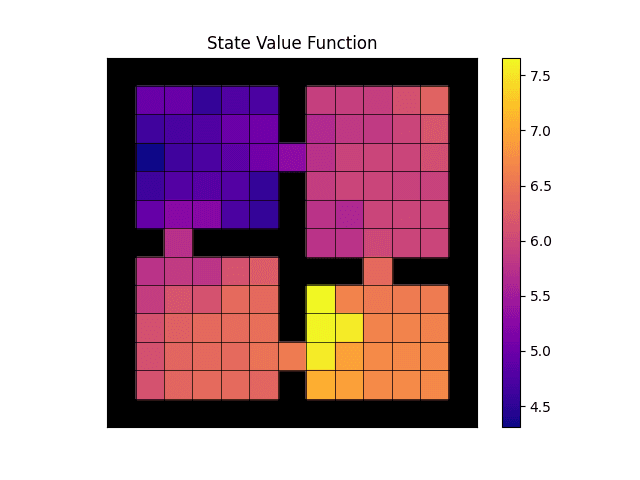
State-value function.